
Data-Driven or Hypothesis-Driven?
Data-Driven Life Science. Data-Driven Biology. Data-Driven Research.
(This write-up is a reflection from the two internal talks that I gave this week.)
We hear this term a lot lately. Over the past decade or two, we have witnessed a data explosion in biomedical research. The decreasing costs of omics data generation and computing power are major drivers of this trend. Naturally, with big data, biological research has become more appealing to researchers from other, more data-intensive fields, such as mathematics, physics, and computer science. This shift has really propelled the rise of the data-driven paradigm in biological research. But what does it really mean? What is the advantage? How does it differ from “the other” biology? Is it better? Let’s try to answer these questions.
Hypothesis-Driven Research: Old but Gold
Most biological research begins with a hypothesis. But what is a hypothesis? Simply put, it is an educated guess or a hunch. For example, a scientist may suspect that X causes Y. They then design experiments to test this hypothesis, measure relevant variables, and analyze the evidence. The results will determine whether the hypothesis is supported or not. This approach is known as hypothesis-driven research.
With a hypothesis, researchers can frame their studies and focus on a specific set of related variables and processes. This paradigm has been a cornerstone of scientific research, not only in biology, for thousands of years and has led to groundbreaking discoveries, such as radioactivity (Curie), relativity (Einstein), and penicillin (Fleming).
Data-Driven: The Future of Biomedical Research
In the past two decades, high-throughput data that measure hundreds or thousands of variables simultaneously have become cheaper and more accessible. This type of data is called omics data. As I mentioned earlier, this, along with increased computational power and interdisciplinary collaboration, has led to the rise of a new paradigm: data-driven research.
Instead of starting with a hypothesis, data-driven research begins with a question—such as "What causes Y?" To answer this, we analyze datasets containing thousands or even millions of variables. We then apply statistical analysis, network analysis, and machine learning techniques to identify differences between groups, uncover relationships between variables, and detect patterns in the data.
This analysis allows us to generate a systems-level model that provides a more comprehensive view of the system rather than focusing on isolated subsystems. This approach helps uncover insights that might otherwise be missed when focusing on a single subsystem in isolation.
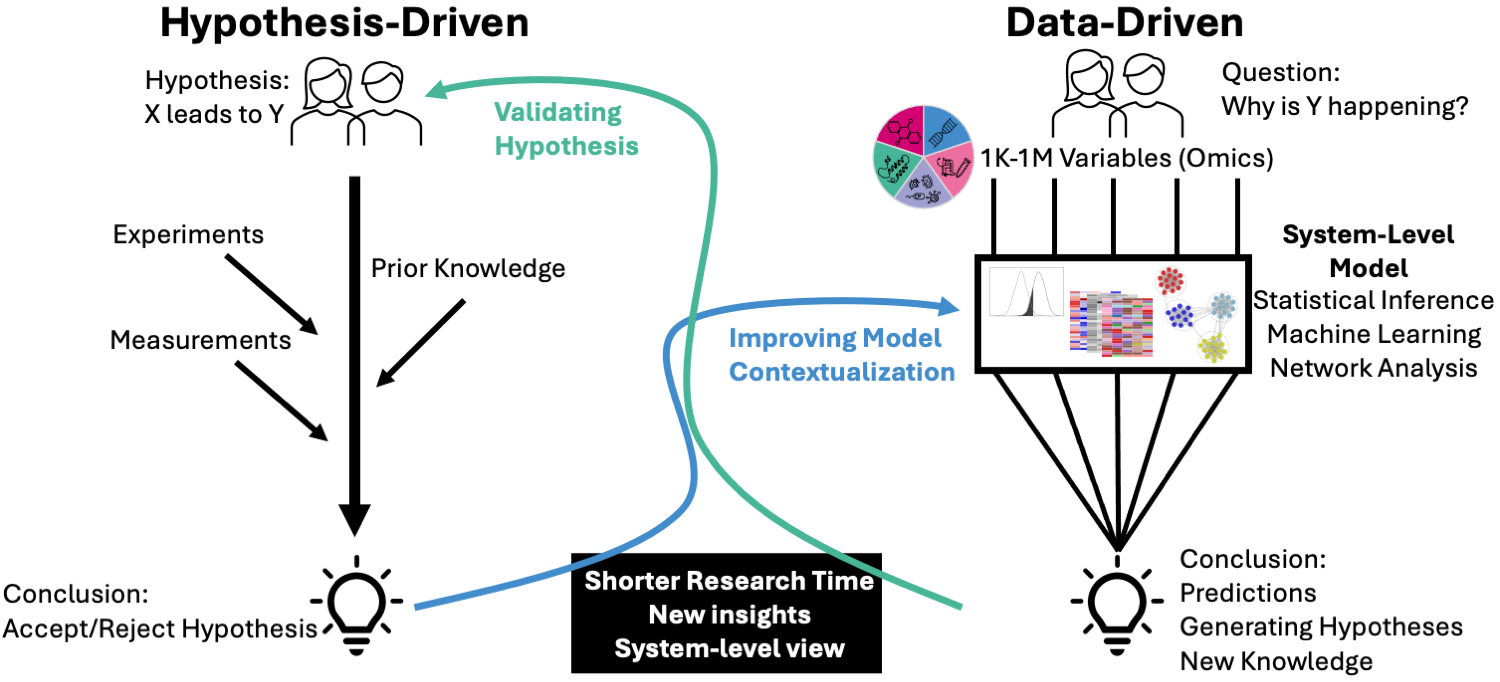
Hypothesis-Driven and Data-Driven: Friend or Foe?
One is not better than the other. Rather than debating the pros and cons of each paradigm, I want to highlight how they are deeply intertwined. Data-driven research often generates new hypotheses, which is why it is sometimes called hypothesis-generating research. These hypotheses must then be validated through experiments to determine whether they should be accepted or rejected—bringing us back to hypothesis-driven research. In turn, the outcomes of hypothesis-driven research help refine systems-level models and provide context for data-driven research.
Hypothetical Example: Candy in Our Body
Imagine a researcher from a university studying the effects of excessive candy consumption on the body. They generate omics data from cells (in vitro) or animals (in vivo) exposed to higher sugar levels in culture media or diet. Using statistical or machine learning analysis on 20,000 measured variables from the omics data, they create a large-scale map of how the body responds to candy consumption. From this map, they identify a new receptor, X, that appears to be associated with higher sugar intake.
Based on this finding, they develop a hunch that blocking receptor X could reduce sugar consumption. To test this, they conduct experiments where receptor X is blocked in vitro or in vivo, followed by sugar exposure and consumption measurement. However, their results show that even after blocking the receptor, sugar consumption remains the same. This suggests that increased levels of receptor X are a consequence of higher sugar intake, not the cause. With this insight, they refine their original model and develop a new hypothesis for further testing.
This is an example of modern biomedical research, where both wet-lab (experimental) and dry-lab (computational) scientists collaborate to enhance research effectiveness. Without the data-driven approach, researchers may never have identified the association between receptor X and sugar consumption. And without hypothesis-driven research, they might have wrongly concluded that receptor X was the cause of higher sugar consumption.
Conclusion: The Best of Both Worlds
The rise of data-driven research has transformed biomedical science, allowing us to uncover hidden patterns and generate new hypotheses. However, data alone is not enough. Without hypothesis-driven research, we risk misinterpreting correlations as causation or missing critical biological mechanisms. True scientific progress happens when these two approaches work hand in hand.